
سلام. من مهدی، بکاند دولوپر مجموعه دیتاک هستم. در این پست قصد داریم جزئیات مهاجرت از socket.io به SSE یا server-sent events را باهم بررسی کنیم و از دلایل این مهاجرت تکنولوژی صحبت کنیم. با من همراه باشید. در وهله اول چرا Socket.io؟ تقریبا ۴ سال پیش نیاز به ارسال نوتیفیکیشن در اپلیکیشن ما به وجود اومد. خروجی های سنگینی مثل بولتن، اکسل و… وجود داشت که به درخواست کاربر پشت پرده انجام میشد و ما نیاز به راه آسانتری …
پست وبلاگ

سلام به همهی دنبالکنندگان بلاگ مهندسی دیتاک.در این مقاله قصد داریم به یکی از قابلیتهای ابزار الستیک سرچ به نام Analyzer بپردازیم. ما در تیم فنی دیتاک با استفاده از این قابلیت و بهینه سازی آن …

همراهان گرامی دیتاک، سلام امیدوارم حالتان خوب باشد. مدتی بود دوست داشتم پستی در ارتباط با تیمهای فنی که در شرکت در حال فعالیت هستند بنویسم و شما را کمی بیشتر با تیمها آشنا کنم، اما …
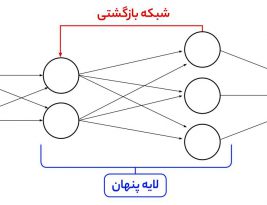
امروزه استفاده از الگوریتمهای یادگیری عمیق (Deep Learning) در حل مسائل یادگیری ماشین (Machine Learning ) بسیار پرکاربرد شده است. با افزایش حجم دادهها و کیفیت بالای به دست آمده و قدرتمندتر شدن سیستمهای پردازشی، استفاده …

شاید اسم apache airflow به گوشتان خورده باشد. airflow به صورت خلاصه یکی از ابزارهای مدیریت پیشرفته ی workflowهای سازمانی است. اگر می خواهید در این رابطه بیشتر بدانید، پیشنهاد میکنم قبل از خواندن این مقاله …

در ابتدا بگویم که اگر این مقاله را میخوانید که بدانید OrientDB چه قابلیتهایی دارد و چهکار میکند، شما را به سایت و داکیومنت این محصول ارجاع میدهم که بسیار بهتر از من به بیان قابلیتها …
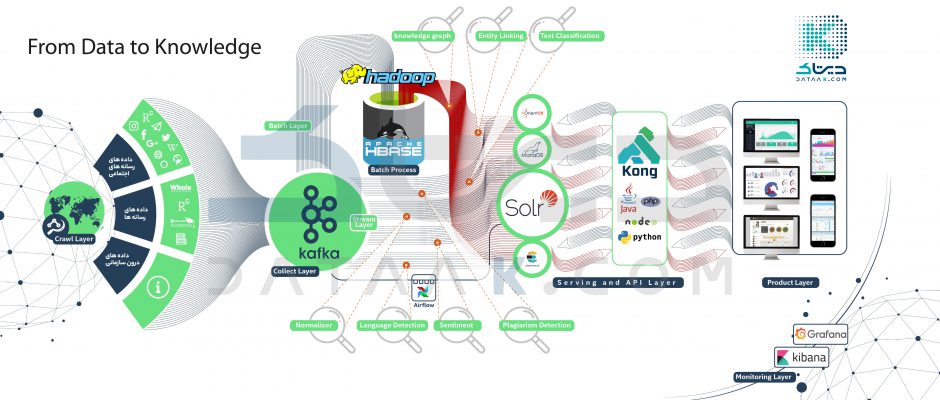
سلام من هامون، مدیر فنی شرکت دیتاک هستم. در این پست میخواهم شما را با معماری بیگ دیتای شرکت دیتاک بیشتر آشنا کنم. ما در ابتدا چه میکردیم!؟ مانند بسیاری از مجموعههای دیگر، کار مجموعهی ما …
امروزه حجم عظیمی از دادههای موجود را فعالیتها و اطلاعاتی که کابران در فضای مجازی به اشتراک میگذارند، تشکیل میدهد. این دادهها میتوانند از منابع متنوعی همچون شبکههای اجتماعی، دادههای ابری، اینترنت اشیا و هر منبع …

داستان مهاجرت به اسکریپی: ما قبل از اسکریپی، انجینی را برای جمع آوری استفاده میکردیم که از PHP قدرت گرفته و از پایه توسط تیم فنی دیتاک توسعه داده شده بود. با توجه به حیاتی شدن …