
سلام به همهی دنبالکنندگان بلاگ مهندسی دیتاک.
در این مقاله قصد داریم به یکی از قابلیتهای ابزار الستیک سرچ به نام Analyzer بپردازیم. ما در تیم فنی دیتاک با استفاده از این قابلیت و بهینه سازی آن توانستیم به بهبود مناسبی در جستجوی متون فارسی دست پیدا کنیم. همچنین با این روش توانستهایم ۴۰ درصد در فضای ذخیره سازی صرفه جویی صرفه جویی کنیم.
تعریف مسئله
اِلستیک سرچ به عنوان زیرساخت ذخیرهسازی و جستجو در دیتاک مورد استفاده قرار گرفته است.
جستجوی متنی یکی از پایهایترین ویژگیهای سامانه است که می بایستی بدون خطا و با سرعت مناسب، نتایج را در اختیار کاربر قرار دهد.
یکی از دلایل استفاده از این ابزار، بهینه بودن آن در جستجوی متنی و استفاده از موتور lucene است که قابلیت جستجوی سریع بر روی میلیاردها دیتا را فراهم میکند.
اگرچه موتور Lucene دقت خوبی در جستجوی متنی دارد، اما در زبان فارسی مواردی وجود دارد که نیازمند مدیریت آنها در زمان جستجو است.
در زبان فارسی، یک کلمه ممکن است نوشتارهای متفاوتی داشته باشد.
به عنوان مثال؛ آمریکا، آمریکا یا انواع نوشتارهای «ی»، «یی»، «ئ» و… که در شبکههای اجتماعی به طور گسترده استفاده میشوند.
برای اطمینان از نمایش نتایجِ کامل به کاربر، لازم است که جستجو بر روی دادههای نرمال شده انجام شود. از طرفی، متن محتوای جستجو شده باید به کاربر به همان شکلی که در شبکههای اجتماعی منتشر شده است نمایش داده شود.
راه حل اولیه
برای تضمینِ درستیِ نتایجِ جستجو، عملیات نرمال کردن دادههای ورودی میبایستی انجام شود.
به این منظور، تمامی کاراکترهایی که بایستی حذف شوند تشخیص و جایگزین آنها نیز مشخص شده است.
در اینجا به عنوان مثال، ۴۵۸ کاراکتر است که بایستی نرمال شوند.
در همین راستا، در معماری دیتاک یک سرویس توسعه داده شد که با دریافت متن و با توجه به قوانین تعیین شده، نسخه نرمال شده را برگرداند.
از این سرویس در فرایند ETL و به عنوان یک لایه Transformer به عنوان Normalizer استفاده میشود.
نسخه اصلی: صحبت های آتیلا پسیانی در مراسم رونمایی از کتاب زنده یاد ناصر حجازی + فیلم
نسخه نرمال شده: صحبت های اتیلا پسیانی در مراسم رونمایی از کتاب زنده یاد ناصر حجازی + فیلم
از این پس از متن نرمال شده برای جستجو استفاده می شود. بنابراین این متن نیز بایستی در دیتابیس ذخیره و ایندکس شود و کوئری های جستجو بر روی این فیلد اعمال شود. از طرفی دیگر، متن اصلی نیز برای نمایش به کاربر بایستی ذخیره شود.
یکی از مشکلات این روش Data redundancy بود. قسمت اصلی داده های شبکه اجتماعی (پست ها) متن مطلب است و داده های دیگر مانند تعداد لایک، زمان انتشار و غیره حجم بسیار کمی را اشغال می کند.
به عبارتی، با ذخیره سازی یک نمونه نرمال شده از متن هر داده، تقریباً دو برابر فضای مورد نیاز توسط هر داده اشغال شده است.
به عنوان نمونه، داده های یک سالِ پُستِ بستر اینستاگرام با این روش ذخیره سازی ۶۸۰ GB فضا را اشغال کرده است.
نکته: ذخیره سازی تصاویر در سرویس Object storage است و حجم آن در اعداد این مقاله محاسبه نشده است.
یکی دیگر از سربار های این روش، سربارِ زیرساختی است. به ازای هر دسته(Batch) از داده بایستی سرویس نرمالایز که از طریق یک API قابل دسترس است استفاده شود. این کار هم پهنای باند شبکه و هم منابع سروری را اشغال می کند.
الستیک و نرمالایزر
برای حل این مسئله بهتر است ابتدا به نحوه ذخیره سازی داده و عملیات جستجو در الستیک سرچ بپردازیم.
الستیک سرچ برای جستجو، ایندکس کردن مقادیر یک داده از ساختار داده ای با نام Inverted index استفاده می کند. در این فرایند متن Tokenize شده و هر Token ذخیره می شود. به عبارتی دیگر یک ساختار Hashmap است که هر کلمه به داکیومنت هایی که در آن وجود دارد اشاره میکند.
در تصویر زیر مثالی از این ساختار آمده است:
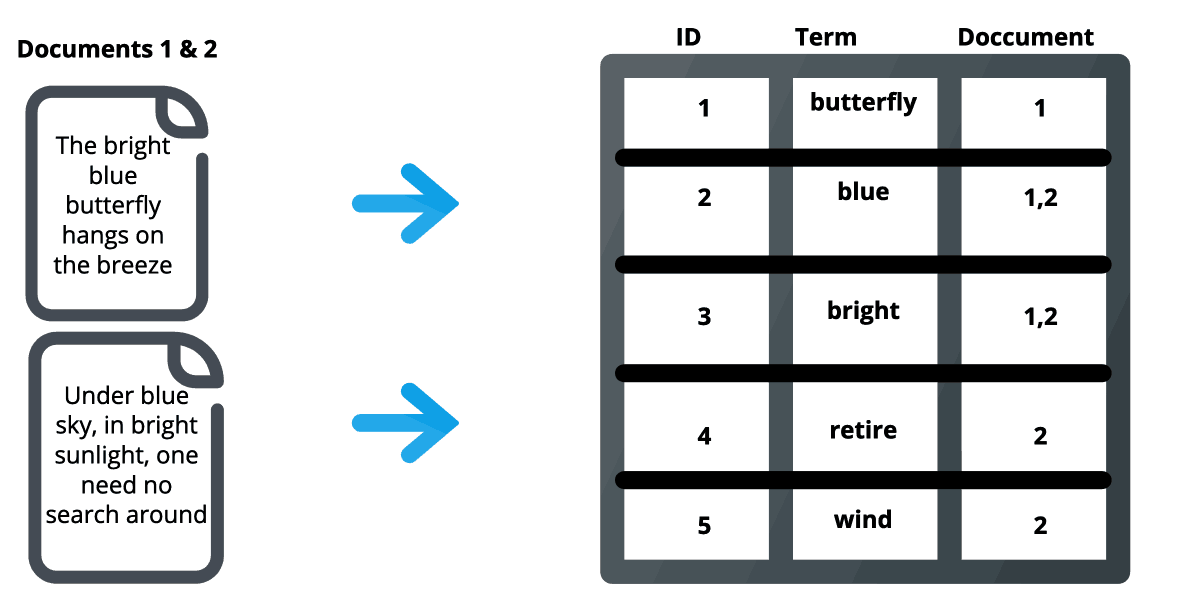
جستجو بر روی این کلمات نیز اعمال میشود و داده مورد نظر برگردانده میشود. بنابراین کافی است دادهها را به صورت نرمال ایندکس کرد و تنها متن نرمال نشده را ذخیره کرد. با این روش در زمان جستجو، کلمه به صورت نرمال جستجو میشود اما نتیجهی متن منتشر شده است.
در این لینک می توانید بیشتر راجع به نحوه ایندکس شدن داده در الستیک سرچ بخوانید.
ابزار الستیک سرچ ویژگی ای با نام Analyzer را معرفی کرده است. این ویژگی قابلیت تغییر بر روی متن را به ما می دهد و می تواند توکن ها را قبل از ایندکس کردن تغییر دهد.
به عنوان مثال؛ می خواهیم اعداد فارسی را به اعداد انگلیسی تبدیل کنیم. الستیک به ما این قابلیت را می دهد تا یک Mapping را برای جایگزینی حروف تعریف کنیم.
به عنوان نمونه از Analyzer برای تبدیل اعداد فارسی به انگلیسی استفاده می کنیم. الستیک سرچ پس از Tokenize کردن جمله ورودی با توجه به Mapping فراهم شده، حروف را جایگزین می کند.
با ایجاد فایل مربوط به Mapping، کاراکتر های نرمال و غیر نرمال آن ها را در تنظیمات ایندکس قرار دادیم و مشخص می کنیم که کدام فیلد از این Analyzer استفاده کند.
در دیتاک، تمامی متن های پست های شبکه اجتماعی از این Analyzer استفاده می کنند و نسخه نرمالایز شده آن از دیتابیس حذف شده است.
همچنین برای جستجوی متن بر روی داکیومنت، نیازی به نرمال کردن کوئری کاربر نمی باشد و الستیک قبل از جستجو، ورودی کاربر را نرمال می کند و حالت نرمال شده را جستجو می کند.
در دیتاک روزانه حدود ۶ میلیون داکیومنت جدید در الستیک ذخیره می شود.
در نگاه اول، انتظار می رفت زمان ایندکس کردن و جستجو بر روی داکیومنت ها به دلیل اضافه شدن بار پردازشی بیشتر شود. برای بررسی این موضوع ۴۰۰ کوئری فعال کاربران سامانه بر روی دو بستر تلگرام و خبر انتخاب شد.
با ۵ تا ۱۰ کاربر همزمان، این کوئری ها بر روی دو ایندکس متفاوت که یکی از analyzer استفاده می کرد اعمال شد که نتایج آن در جدول زیر قابل مشاهده است.
| حداکثر زمان | میانگین زمان | حالت کوئری | نام ایندکس |
| ۰.۶۶۵۴۱۷ | ۰.۰۹۵۴۷۹ | بدون analyzer | خبر |
| ۱.۸۸۷۶۸۷ | ۰.۱۰۱۴۷۵ | با analyzer | خبر |
| ۰.۶۵۸۹۸۸۷۱۴ | ۰.۰۶۵۴۲۶۸۳۸ | بدون analyzer | تلگرام |
| ۱.۷۴۱۳۷۷۸۳۱ | ۰.۰۷۳۴۰۲۸۹۵ | با analyzer | تلگرام |
همانطور که مشاهده می کنید تنها در برخی از کوئری های بسیار سنگین این زمان اختلاف زیادی ایجاد کرده است و به صورت میانگین، اختلاف بسیار کمی با حالت قبلی دارد.
از طرفی دیگر، فضای ذخیره سازی اشغال شده است که با این کار و حذف نسخه نرمال شده متن، ۴۰% از فضای اشغال شده مذکور به ازای هر ایندکس آزاد شد. همچنین با استفاده از ویژگی فشرده سازی الستیک بر روی ایندکس ها توانستیم این عدد را به ۶۰% برسانیم.
